


Following the last month launch of the Gemma 3 open AI model, new versions of Gemma 3 optimized with Quantization Aware Training (QAT) have just been announced by Google. The new versions will be making Gemma 3 more accessible to developers.
Read more about it below.
Gemma 3 QAT Models Announced, Bringing the Best AI Capabilities for Consumer GPUs
While the initial Gemma 3 model became a leading AI model that is capable of running on a single high-end GPU such as the NVIDIA H100 making use of the native BF16 (BFloat16) precision, its new versions that have been optimized with Quantization Aware Training (QAT) reduces memory requirements and enables it to run on consumer GPUs like the NVIDIA RTX3090. Thus, Gemma 3 is made accessible to more developers, letting them use it on the consumer-grade GPUs that are already there in their desktop PCs, laptops, and also phones.
Speaking more, with quantization, the precision of numbers stored and used is reduced. Meaning, instead of 16 bits per number (BFloat16), 8 bits per number (int8) and 4 bits per number (int4) can be used. When using 4 bits, data size is reduced by 4 times when compared to that of 16 bits. Also, to avoid degradation due to quantization, Google has made its Gemma AI models robust to quantization, and several quantized variants for the Gemma 3 models have been released.
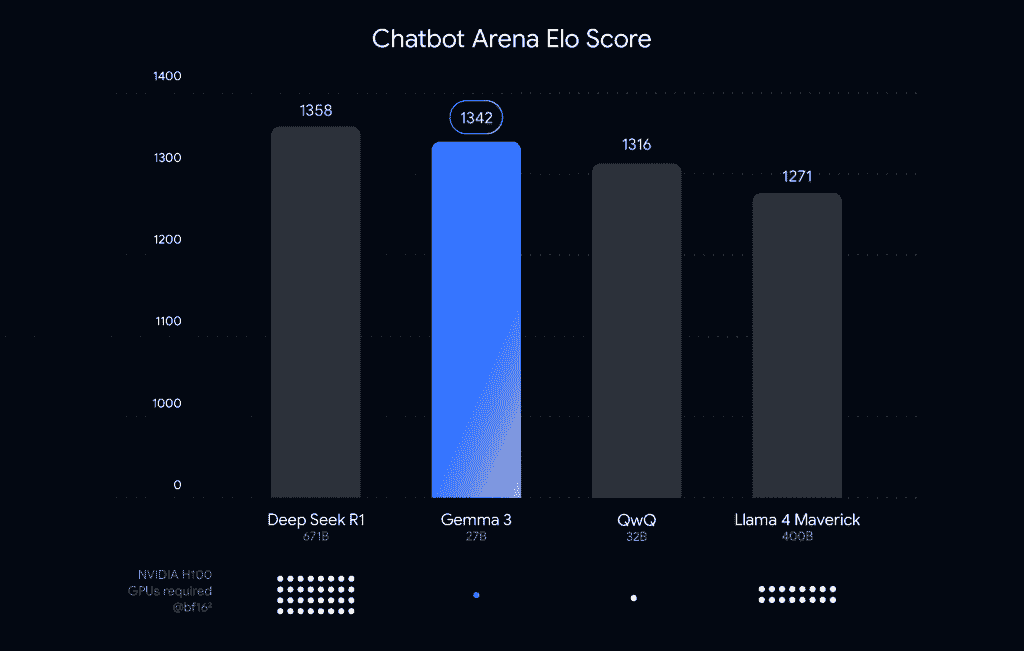
About the VRAM or GPU memory required to load the model weights in int4, in Gemma 3 27B it is reduced to 14.1 GB, in Gemma 3 12B it is reduced to 6.6 GB, in Gemma 3 4B it is reduced to 2.6GB, and in Gemma 3 1B it is reduced to 0.5GB. Looking at the Chatbot Arena Elo Score, the latest Gemma 3 27B model has achieved a performance score of 1342 points, revealing it to be better than Alibaba Cloud’s QwQ 32B (1316 points) and Meta’s Llama 4 Maverick 400B (1271 points), and closely powerful when compared to the DeepSeek R1 671B (1358 points).
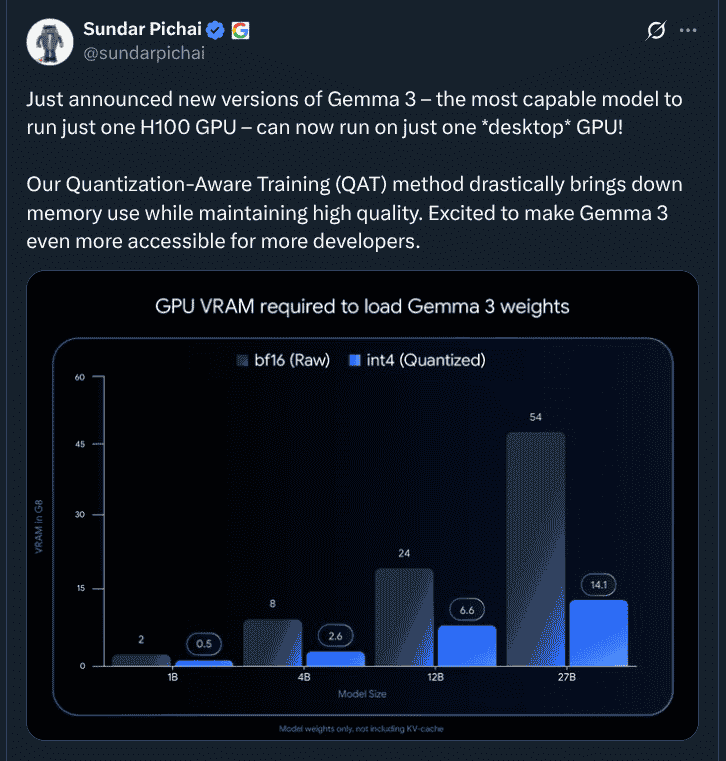
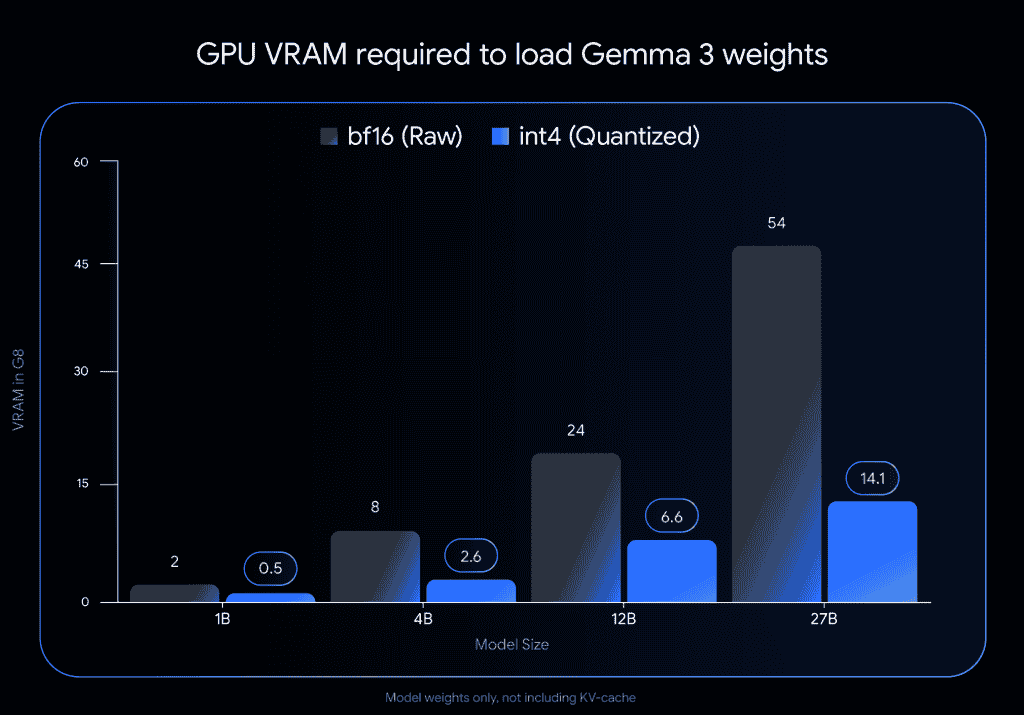
Regarding running the Gemma 3 models on devices, the Gemma 3 27B (int4) can be used on a single desktop NVIDIA RTX 3090 (24GB VRAM) or similar GPU card, the Gemma 3 12B (int4) can be used on laptop GPUs which include NVIDIA’s RTX 4060 Laptop GPU (8GB VRAM), while the Gemma 3 4B and Gemma 3 1B smaller models can be used in resource-constrained devices like phones and more.
Popular tools like Ollama, LM Studio, MLX, Gemma.cpp, and llama.cpp can be accessed to complete the integration process. To note, Google’s official int4 and Q4_0 unquantized QAT models will be available on Kaggle and Hugging Face. More alternatives are also available in the Gemmaverse as well, and these are readily available on Hugging Face too.


