OpenAI New Open-Weight ‘gpt-oss-120b’ and ‘gpt-oss-20b’ Models Introduced; Trained on NVIDIA GPUs; Available Now on AWS Via Amazon Bedrock and Amazon SageMaker AI

The American AI tech brand – OpenAI has now introduced two of its new advanced open-weight reasoning models. These open models were trained making use of NVIDIA’s GPU, and they are currently made available on AWS as well.
Here’s more about it.
OpenAI’s New ‘gpt-oss-120b’ and ‘gpt-oss-20b’ Open-Weight Models
As mentioned, two new open-weight models have been introduced by OpenAI and these include the ‘gpt-oss-120b’ and ‘gpt-oss-20b’ models. The former is a large open model that is designed for use in data centers as well as on high-end laptops and desktops, whereas the latter is a medium-sized open model that has been designed for most laptops and desktops. Both the models are also supported by the Apache 2.0 license, which enables users to create freely without any copyleft issues or patent restrictions. Moreover, the two models are designed for agentic tasks and they are deeply customizable with low/medium/high reasoning adjustments. Users can also easily access the full chain of thoughts too.
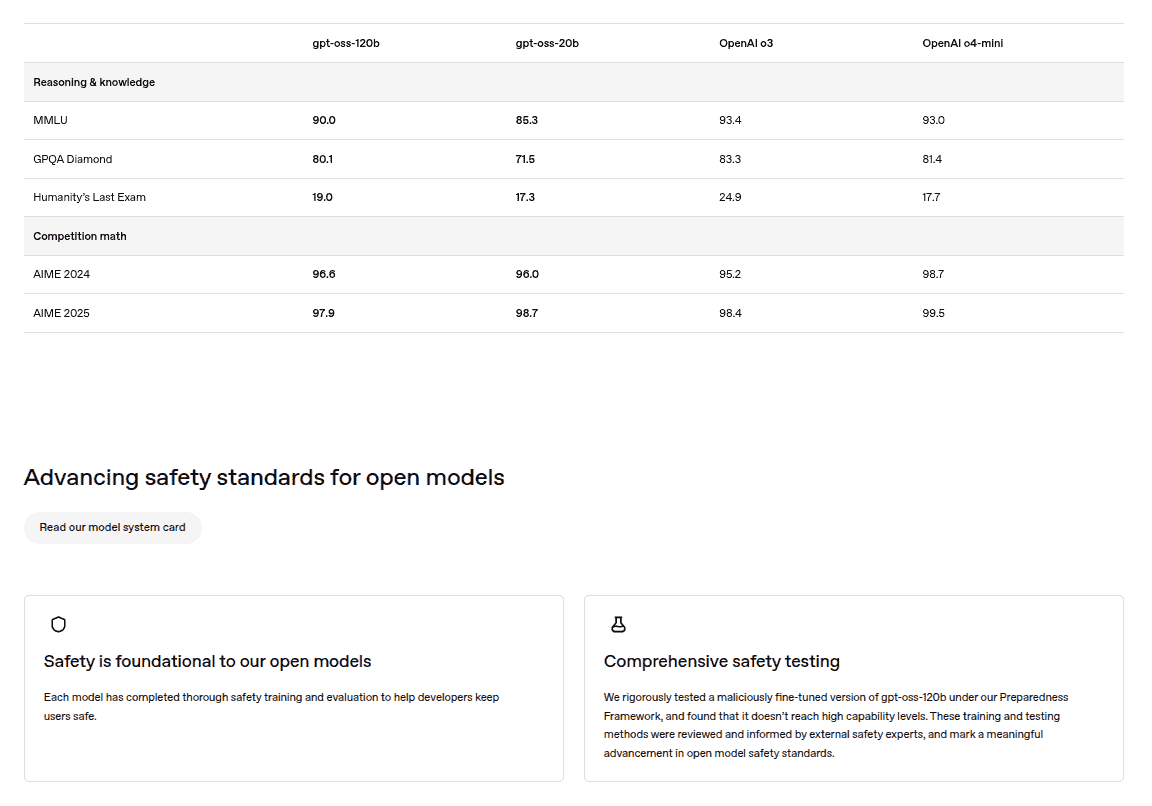
Regarding their performance, while mostly lower when compared to the OpenAI o3 and OpenAI o4-mini models, the gpt-oss-120b and gpt-oss-20b did perform well on reasoning & knowledge and competition math benchmarks tests. Also, in terms of security, the two models have undergone safety testing and evaluation, and are revealed to keep its users safe.
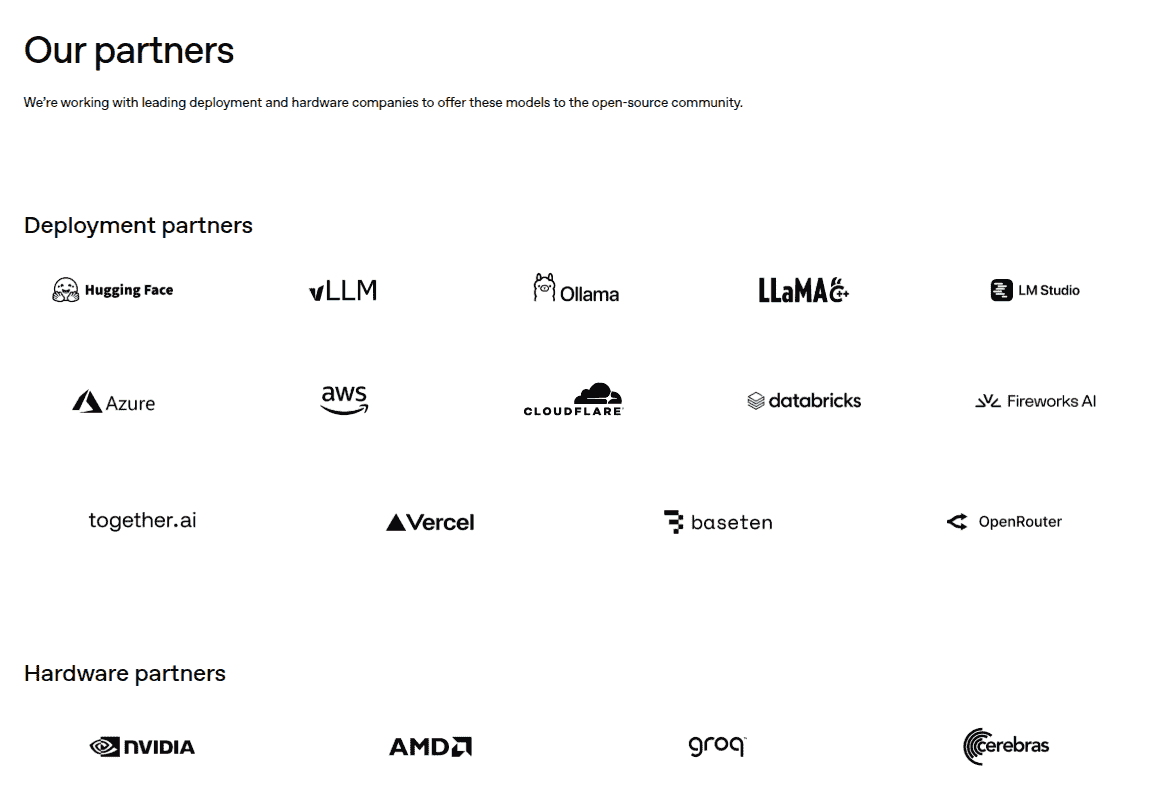
OpenAI has also partnered with several brands to make its new gpt-oss-120b and gpt-oss-20b models available to the open source community. Deployment partners include Hugging Face, vLLM, Ollama, llama.cpp, LM Studio, Azure, AWS, Cloudflare, Databricks, Fireworks AI, Together AI, Vercel, Baseten, and OpenRouter, while NVIDIA, AMD, Groq, and Cerebras Systems are its hardware partners.


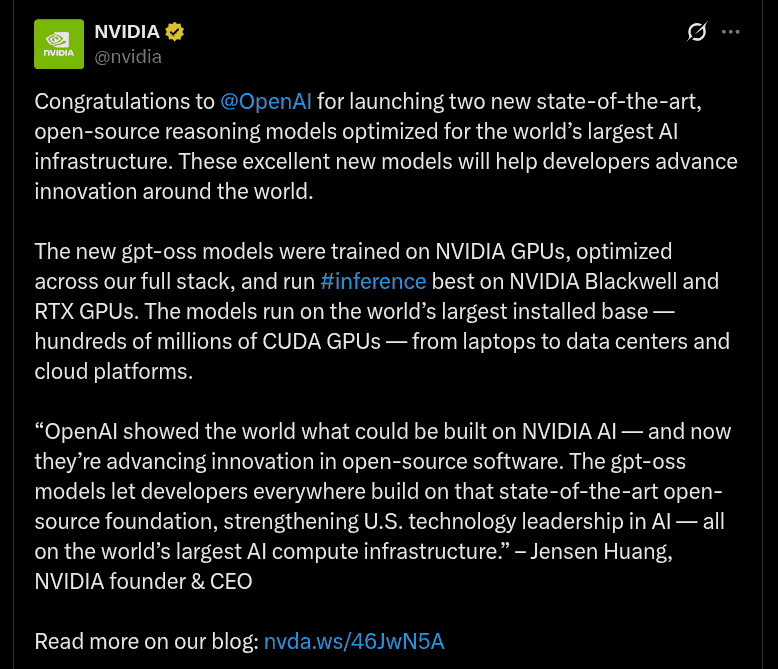
Speaking more, OpenAI’s gpt-oss-120b and gpt-oss-20b models have been trained on NVIDIA H100 GPUs, and are optimized across NVIDIA’s full stack. Also to add, inference runs the best on NVIDIA Blackwell and RTX GPUs (~ 1.5 million tokens per second on a single NVIDIA Blackwell GB200 NVL72 rack-scale system). The mentioned models are now available as NVIDIA NIM microservices.
Additionally, the open-weight models are also now available on AWS (Amazon Web Services), through Amazon Bedrock and Amazon SageMaker AI. To note, the gpt-oss-120b running on Amazon Bedrock is claimed to be 3x more price-performant than the similar Gemini model, 5x more price-performant than the DeepSeek R1 model, and 2x more price-performant than the OpenAI o4 model.

Stay tuned for more updates.
